CMU15-445-Project #2 - B+ Tree Index Checkpoint 1
一些工具
- BusTub B+Tree PrinterCMU官方在线的B+树的生成工具。我主要用来细节实现的时候进行参考。
- JavaScript B+ TreeB+树插入和删除的动态演示。
- Graphviz Online可视化自己的树。在debug的时候会用到。将生成的dot文件转换成svg图片。
- Log In | Gradescope在线评测网站,邀请码:PXWVR5,
- Project #2 - B+Tree | CMU 15-445/645 :: Intro to Database Systems (Fall 2022)最重要的当然还是课程网站了
- 课程的视频,还有对应的教材还是推荐看一下的上面有很多实现细节的。非常值得参考。
如何Debug自己的🌳
大致上可以分为两种方式
- 可视化的用自带的
printer将树生成dot文件然后复制到上面的可视化网站。 - 由于本项目采用的是cmake构建的,所以可以很方便的在测试文件中打上断点。进行调试。
可视化调试
在终端中执行以下命令,构建和执行printer。
1 | |
执行完之后就会有以下提示:

按照这个提示就可以生成dot文件,然后复制到上述的网站进行可视化。(当你看到自己的树呈现出来的时候还是非常有成就感的😁)
非可视化

可以很方便的直接打断点,然后在vscode中的cmake插件中选择调试进行debug。
官方还提供了一种大打log的方式进行debug,我是不太习惯这种方式所以没有进行很深入的研究。感兴趣的可以自己进行了解😗。
两种debug的方式是相辅相成的,在你过不了本地样例的时候好好的用非可视化的方式进行debug,线上样例过不了大部分原因是细节处理上出问题了。用可视化的方式会更加的直观。
请不要公开代码,尊重Andy劳动成果
概览
Project2是实现B+树索引,整个project大致被分为了两个部分
- checkpoint1:实现一个单线程的b+树。
- checkpoint2:实现一个多线程的b+树。
实验代码中给出的自由发挥的空间非常的大,只给出了Getvalue(),Insert(),Remove()这三个函数的接口,剩下的所有的实现都非常的自由,整个实验实现的过程就像一个黑盒一样,只在乎输入和输出。

本实验需要完成b+ index部分,b+树中的页(page)都需要从上一个实验中实现的buffer pool中取。
Checkpoint-1
Task #1 - B+Tree Pages
需要完成以下三个page,主要都是一些getter和setter的函数,重在理解各部分的组成。
其中parentPage是internal page和leaf page的父类。我更倾向于把这几个page类型理解为 从buffer pool中取回来的Page的不同解释形式。Page还是那个Page。主要就是在于你如何去解释它的组成部分。
Page的组成
首先回顾一下在P1中就已经接触到的Page。这个Page我理解为数据在disk上的存储单位。相当于一个计量概念。
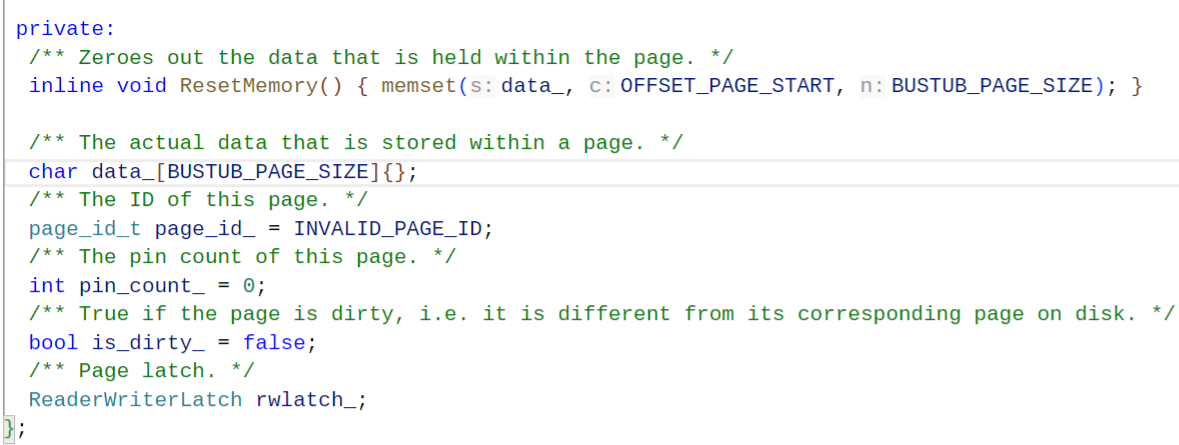
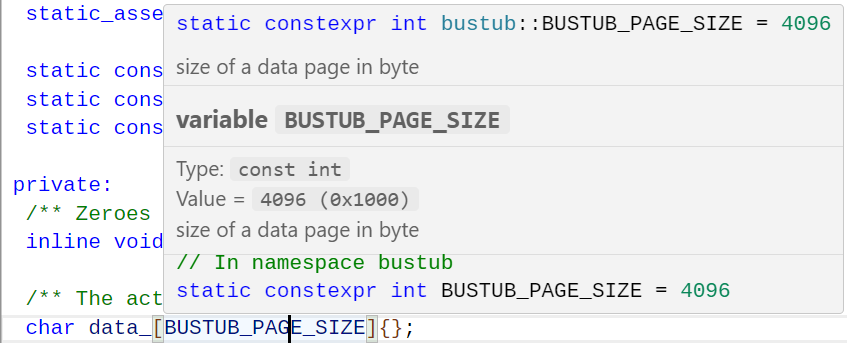
可以看出这个data_数组的大小为4096B即4KB。这个大小是定义的常量BUSTUB_PAGE_SIZE决定的。
本项目的所有的数据都是在data_中的。-----我理解的就是对data数组中的数据解释方式不同。
BPlusTreePage
这是internal page和leaf page的父类b_plus_tree_page。
1 | |
以上部分组成了两种节点的公共部分,共占据24B,还剩下4KB-24B的空间,但是如何使用这剩下的空间呢?
可以从下面的这个flexible数组找到答案。这个大佬解释的比较的详细,我也是在这看到的。做个数据库:2022 CMU15-445 Project2 B+Tree Index - 知乎
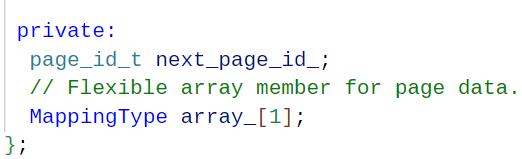
众所周知,数据在数组中的排列是连续的,可以通过下标一直向下进行访问,就是通过利用这个特性使用头指针加上偏移量就到准确的找到我们想要的那个数据。
因此我认为这个array_数组相当于提供了一个使用剩下空间的一个入口,有个这个门把手就可以轻松的使用剩下的空间。
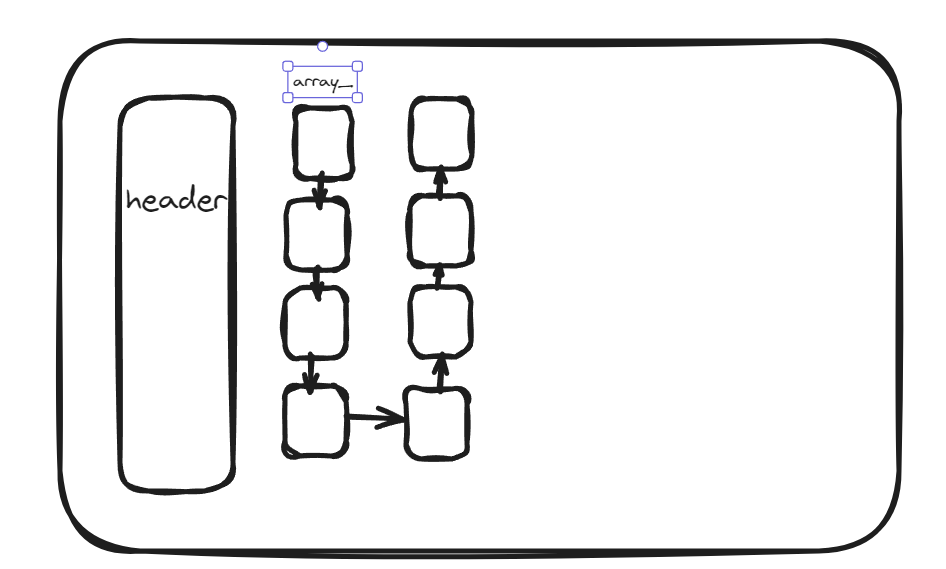
大致可以认为数据就是以上的这种形式。每一个小方格都是一个kv对。
今天我在网上冲浪的时候发现了更加详细的关于柔性数组的信息。

截图自C语言结构体里的成员数组和指针 | 酷 壳 - CoolShell。
同时这篇文章也贴出了文章出处Zero Length (Using the GNU Compiler Collection (GCC))。
现在细细想来这篇博客我很早其实就看到过,但是在当时我总觉得这些都是一些语法糖罢了,没想到自己错失了很多学习的机会。🤤
Internalpage
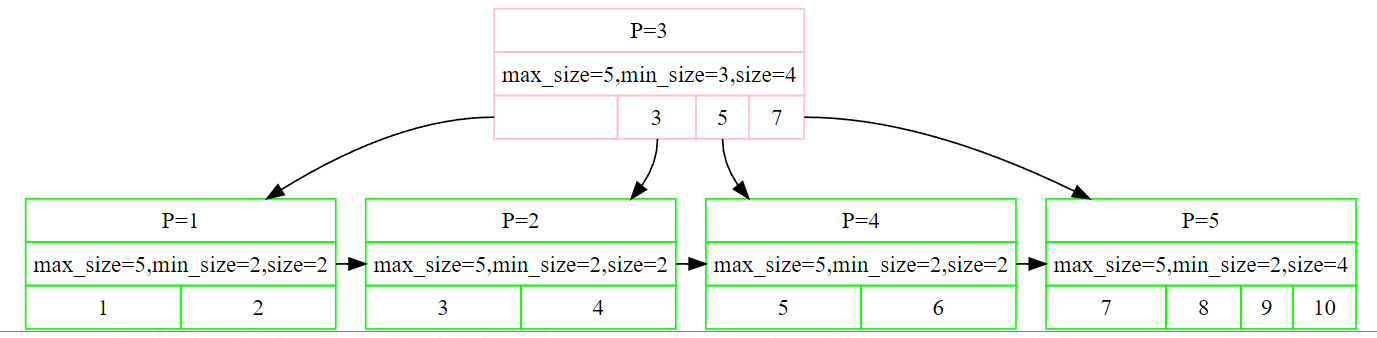
上图中红色的就是internalpage。
我们发现第一个key是空着的,但是value指向了小于value(1)的page。其实internal的value存放的是pageid。
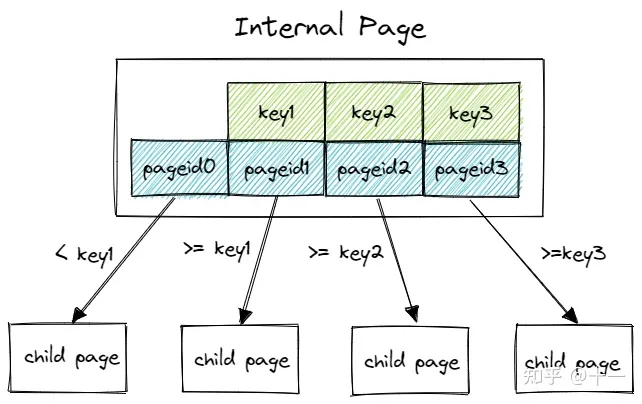
所以internalpage的第一个key要置空处理,其实最后一个置空也可以了,只要能自洽就可以了。
需要注意的是:这里只存放孩子节点的pageId,找到这个id之后取buffer pool里取
LeafPage
基本组成和这个internalpage是一样的,多了一个next_page_id.
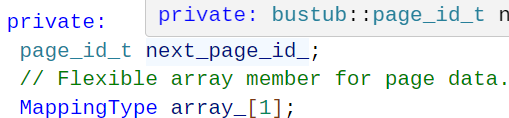
这个next_page_id用与指向相邻的叶子节点,从上图中绿色叶子节点的指针就能看出来。
这个的主要作用就是能够进行遍历。
需要说明的一点是:在叶子节点中key是索引,value是recordId,这种形式也就是二级索引
在数据库中需要拿到这个recodeId之后返回表中进行查询。大大加快查询的速度。
我觉得二级索引有以下几个优势:
- 更新的代价很低:因为value都只是一些id所以占得空间很小,处理起来开销自然就小了。
- 一张表能够组织多个索引:更换不同的key就能组织起来一个索引。
Task1的内容很简单,基本就上述这些,主要是弄清楚page的组成,和框架的构建。被折磨了这么多天的我真心建议多用提供的工具画一些树先不要着急动手,想清楚每个部分的组成和作用再下手也不迟,正所谓磨刀不误砍柴工。
补充一点
聚簇索引和非聚簇索引(二级索引)
一言以蔽及:聚簇索引的value就是你想要找的数据或者是数据所在的页本身,非聚簇索引存放的相当于是你想要的数据所在位置的快速指针帮助你快速定位。
Task #2 - B+Tree Data Structure
task2是checkpoint1的重头戏,非常的有意思。
有几个需要注意的点:
- 要求此b+树的索引是唯一的,不支持重复的插入。
UpdateRootPageId在root_page_id发生改变的时候需要调用已经实现好的这个函数,保证树的持久化。- 在实现的时候一定多多考虑实现的细节,比如每种节点的最大最小值,
插入后的键/值对的数量等于叶节点的max_size,插入前的子节点的数量等于内部节点的max_size。
下面按照函数的顺序进行介绍。
在介绍函数之前我想说明一下Transaction这个类的作用。顾名思义,这个Transaction被翻译为事务。在这篇文章中对这个事务有着详细的介绍。[[查询的处理和优化]]。

在这个类中实现了很多函数,可以把需要处理的page放在实务中等结束了进行统一的处理。因为在函数中涉及到很多的fetch和unpin,而且函数还有递归嵌套,处理起来是非常的麻烦,所以我建议直接尝试使用transaction,反正后面也要用。 ^d53eec
GetValue()
GetValue()
写到这里的时候理应对b+树的结构非常的了解,其实也就是两种节点,一种是internal,一种是leaf,从root节点开始寻找每一个节点中最后一个<=输入key的值。然后找到key所在的leaf节点,从前向后遍历,找到想要的值。下面是一个模拟示意图👇。
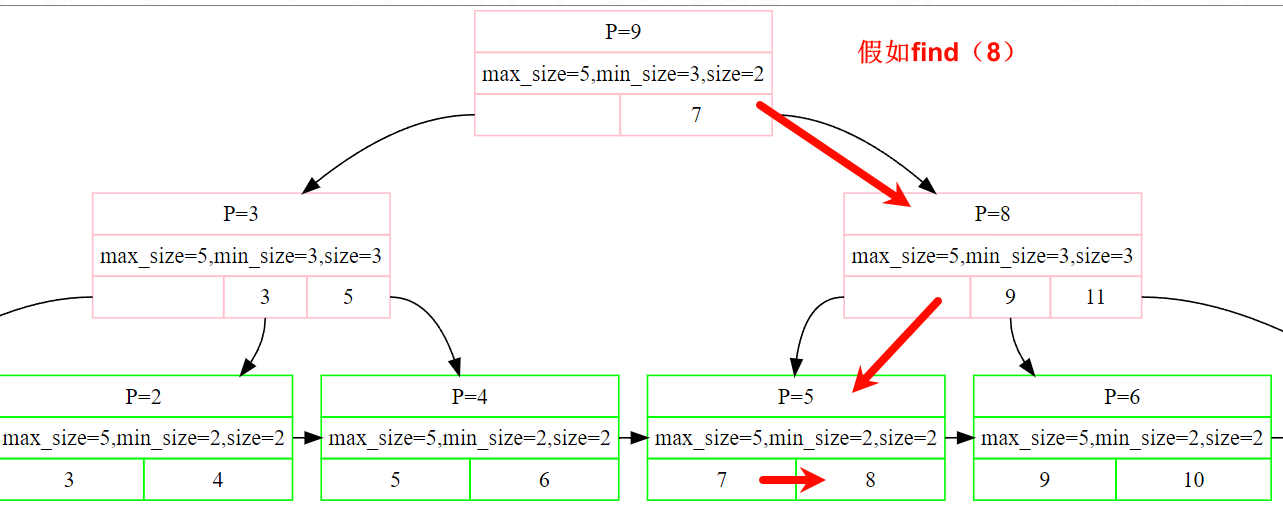
其实无论我们是查找,插入,还是删除,首先都必须找到key所在的leaf节点。由此可以将上面这个寻找key所在的leaf节点的过程封装出一个使用频率极高而且非常重要的函数:FindLeafPage()。我们从书上给出的伪代码和上述模拟过程对照分析。

虽然说我们要找的是最后一个<=输入key的值,但是在具体的伪代码实现中确实寻找第一个>=输入key的值,并进行分类讨论。
1 | |
1 | |
LookUp返回的就是page_id,前面我们也提到过,internal节点的value就是page_id.
这里用到了lower_bound()函数,比自己实现二分查找会方便一些。
但是这个lower_bound函数传入了keycompareter()的比较方法,进行了回调函数的改造,使用类定义的比较规则。不是简单的比大小。

现在找到了key所在的page我们该如何使用这个page呢?
1 | |
通过reinterpret_cast将page解释为LeafPage类型。来供我们进行使用。需要注意的是这种方式非常的不安全,只是将同样的数据进行了不同的解释。只有在我们非常清楚两者之间的关系的时候使用才不容易出错。
找到LeafPage后同样使用上述改造过后的的lower_bound()函数进行查找key😀。
记得UnpinPage
在使用完page之后一定记得unpin不然的话高强度使用过后内存会不足。
我的比较建议还是之前提到的transaction,进行统筹处理,少死点脑细胞。
Insert()
相较于上一个函数而言,insert()的逻辑就相对而言要复杂一些了。
Insert()
插入一个kv对由少到多的情况一个一个进行梳理
- 刚开始树是空的:需要新建一个根节点。
- 有空间能够直接插入
- 插入之后pageSize=leafMaxSize,需要进行分裂,分裂之后将新的page插入到父节点中。
- 有重复的插入,直接返回。
现在再看伪代码大概的情况也是这几种。

对照代码再分析一下:
1 | |

书上给的伪代码是插入之前与(leaf_max_size-1)进行比较,我在处理的时候是插入之后与leaf_max_size进行比较。
⚠️ 这里需要注意的是LeafPage和InternalPage的分裂条件并不一样,也就是说leafpage中最多有(leaf_max_size-1)个kv对,而internal中可以有internal_max_size个kv对。
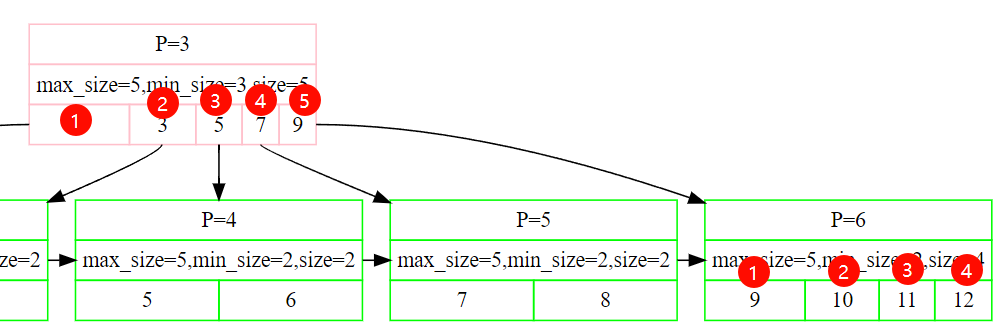
两个的max_size都是5,但是最多的kv对确是不一样的。
InsertIntoLeaf()
1 | |
到这里所有的插入的情况就已经考虑完全了,但是分裂之后需要将新分裂的页插入到父节点中,插入到父节点中之后又涉及到父节点分裂的问题,这就是一个递归嵌套了
InsertIntoParent()

仔细看伪代码的写法,基本是按照伪代码一步步写成的。
1 | |
⚠️ internalPage在分裂的时候尽量创建一个tmp空间进行插入和重新的分配,在本实验中直接在原来的页上插入和分配页没有问题,如果maxsize的大小很极限的话,插入一个kv对可能会容不下,发生错误。
Remove()
remove()函数的逻辑相较于前两个则是复杂非常多的,但是按照伪代码按图索骥,一步一步来,是能够完美实现的。

1 | |
DeleteEntry()
大致梳理一下思路:
- 首先找到页之后自然是删除,需要注意的是leaf和internal的组成略有差异,需要分别进行处理
- 如果所在页是根节点而且只剩下一个子节点需要进行额外的
Adjustroot()函数进行操作。 - 删除之后发现kv对的数量小于规定的
MinSize(),那么进行分类讨论- 和兄弟节点合起来
Coalesce()的大小没有超过maxSize,但是不同类型的节点maxSize计量方式不同,这也是一个坑点,那就将两个节点合并,但是最后记得把被合并的key从父节点中删除 - 和兄弟节点合起来的大小超过了maxSize,那么需要
Redistribute(),从兄弟节点中协调一个过来。这里分成四种情况,是否是叶子节点,以及兄弟节点在前在后分成了四种情况
- 和兄弟节点合起来
⚠️需要注意的是,root page 并不受 min size 的限制。但如果 root page 被删到 size 只剩 1,即只有一个 child page 的时候,应将此 child page 设置为新的 root page。
还有两种类的page计算maxSize的逻辑不太一样需要注意一下。
另外,在合并时,两个 page 合并成一个 page,另一个 page 应该删除,释放资源。删除 page 时,仍是调用 buffer pool 的 DeletePage() 函数。
AdjustRoot()
根节点只剩一个子节点的时候小小的调整一下。
Coalesce()
还是要区分是否是leafPage,处理方式不太一样
如果是leaf节点简简单单的合并到一个节点然后更改一下叶子节点的next指针就够了
如果是Internal节点的话需要合并完之后更新一下子节点的父节点。
Redistribute()
发现不能合并之后就只需要从兄弟节点处协调一个即可
协调的过程比较简单,从左侧节点偷取时,把左侧节点最后一个 KV 对转移至当前节点第一个 KV 对,从右侧节点偷取时,把右侧节点的 KV 对转移至当前节点最后一个 KV 对。leaf page 和 internal page 的偷取过程基本相同,仅需注意 internal page 偷取后更新子节点的父节点指针。
Summary
ckeckpoint1主要的难点就是在细枝末节的处理上,非常的折磨人,我开始没并没有按照严格按照伪代码写,除了很多的奇奇怪怪的bug,最后几乎是推到重来,按照伪代码才算是能正确的运行。
但是unpin我一直处理不好,卡了我好长时间,最后还是祭出transaction,好好研究了一下才把线上评测过了。
最后附上通过截图
也是最这一段时间的一个总结。